

Brixo Newsletter: When AI Bills Hit Different
From AI cost spirals to production reality checks—plus why your test suite won't save you from the real world

Brixo latest
Most LLM evals focus on the obvious metrics. Response quality, speed, cost per token.
But production reveals variables that demos never show.
→ API reliability during peak hours.
→ Integration complexity with existing systems.
→ Actual token consumption patterns across different prompt types.
→ Error recovery behavior when models fail.
Engineering teams are discovering that the models look different at scale.
The "fast" model might have inconsistent latency.
The "cheap" option could require complex retry logic that increases development overhead.
One team we met with found their model performed well on coding tasks but required 3x more tokens for doc generation. Another found that switching to a "slower" model reduced their debugging time by 60%.
Our model assessment framework provides a roadmap for maintaining performance at the right costs.
If you’re building with LLMs, we’re offering a free assessment of your “LLM stack.” We’ll identify opportunities to reduce cost and increase performance. No strings attached.
Reach out to contact@brixo.com or hit the message button below to learn more.
What stood out
The CTO of AISDR, which is one of the prominent AI SDR brands, had this to say about managing their LLM bills:
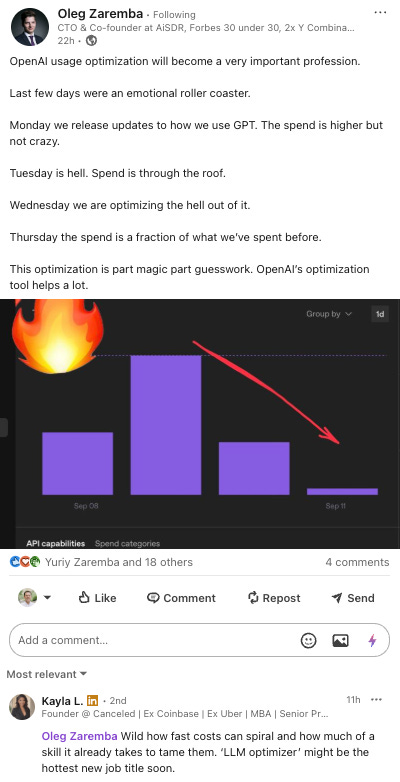
We think every company shipping AI products will do this eventually. Usage is growing fast, but without optimization guardrails, costs spiral out of control.
Remember when iPhone games first launched? Kids racked up massive bills buying in-app items. Parents had no idea until they got the credit card statement. AI feels similar right now.
We're still early, but AI isn't going anywhere. Teams need observability and optimization practices now, before the scary bills show up. Because they will.
What we read/listened/watched
Some great lines from Ben:
"A lot of success is about a small thing, a small thing that's hard to do that doesn't seem to have a high impact. But it leads to the next small hard-to-do thing and then eventually, you get an outcome."
"As CEO, you don't make people great. You find people that make you great."
"No credit will be given for predicting rain. Only credit for building an ark."
One year as an AI Engineer: The 5 biggest misconceptions about LLM reliability I've encountered
Most teams underestimate how different production AI is from their testing environment, leading to expensive surprises when real users interact with their systems.Retry
LLM reliability is a systems engineering problem, not just a model problem. You need proper observability, robust evaluation frameworks, and realistic expectations about what prompting can and can't fix.
When an AI Project goes wrong. A million dollar mistake!
Anyone with enterprise experience will recognize this as typical enterprise behavior. There are always challenges with alignment and expectation setting. But the combination of top-down pressure and lack of general AI knowledge accelerated this outcome, and this will be common.
Vector Databases: The Salesforce for Your Unstructured Data

Vector Databases: The Salesforce for Your Unstructured Data
Final Brick
The brain has about 86 billion neurons. GPT-3 has 175 billion parameters.
But your brain learns to recognize a cat in a few images.
GPT-3 needed 45TB of text.
